08、栈
思考:如何实现浏览器的前进后退操作?
主要内容
栈定义:“操作受限”的线性表,只支持在一端(末尾)进行增加、删除操作,满足先进后出,后进先出的特性。
用数组实现“栈”,一个固定大小的“栈”
1 | |
时间复杂度为 O(1)
空间复杂度为 O(1),虽然存储了大小为 n 的数组,但这是必须的,而空间复杂度指的是算法运行中额外需要的存储空间
栈在函数调用中的应用
操作系统会给每个线程分配内存空间,这块内存被组织为“栈”结构,用来存储函数调用时的临时变量。
进入函数,将临时变量入栈,执行完毕,将临时变量出栈。
举例:
1 | |
对应的栈结构如下: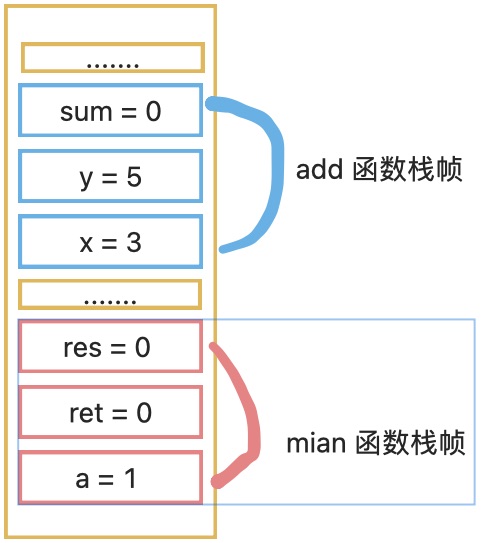
栈在表达式求职中的应用
对于3+5*8-6表达式,人脑很快就能算出来,但编辑器是如何实现的呢?
首先这中表达式它能够理解到就已经是比较难的事了,那又该如何实现计算的呢?
采用两个栈,一个用于存储数据(A)、一个用于存储运算符(B)
当遇到数字,入栈 A;当遇到运算符,先与上一个运算符比较,如果当前的优先级高则入栈 B,否则先取出运算符,然后从 A 取出 2 个数据,进行计算,把结果入栈 A,然后又再比较。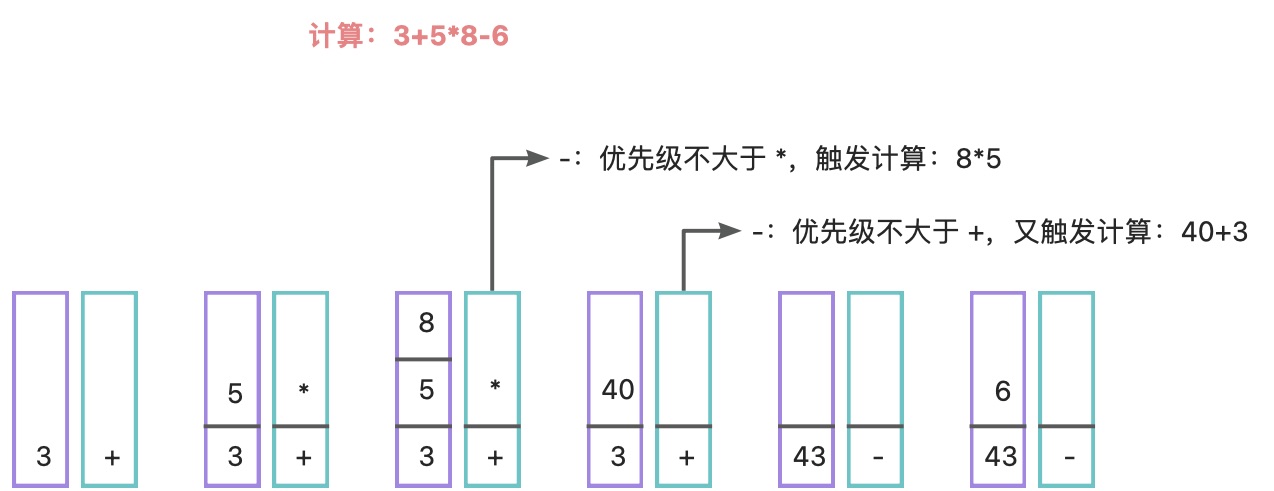
栈在括号匹配中的应用
比如,{[] ()[{}]}或[{()}([])]等都为合法格式,而{[}()]或[({)]为不合法的格式。
那给你一个包含三种括号的表达式字符串,如何检查它是否合法呢?
思路:使用栈来存储左括号。
从左到右扫描字符串,若为左括号则入栈
若为右括号则取出顶层左括号,若未匹配则格式非法,若匹配则继续扫描
最后若栈为空则格式合法,否则格式非法。
解答开篇
如何实现浏览器的前进后退操作?
使用两个栈 X、Y,当首次浏览了页面时,入栈 X。
当点后退时,出栈 X,并将其入栈 Y。
当点前进时,出栈 Y,并将其入栈 X。
举例:一开始浏览了 a、b、c
则 X 为:[a, b, c],Y 为[]
点击后退到 a 时,X 为[a],Y 为[c, b]
此时再点一次前进,则进入 b 页面,其中 X 为[a, b],Y 为[c]
若此时跳转到了 d 页面,则 X [a, b, d],Y 清空变为[],也就无法前进/后退到 c 页面了
新的思考
为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗?
以下答案来自通义千问
函数调用时使用栈来保存临时变量主要是因为栈具有以下几个优点:
- 快速访问:栈是一种线性数据结构,它的主要特点是后进先出(LIFO),这意味着最先进入的数据最后被取出。由于栈的操作只在栈顶进行,所以访问速度非常快。
- 简单高效:栈的插入和删除操作(push 和 pop)只需要 O(1)的时间复杂度,效率非常高。这对于频繁进行函数调用的程序来说是非常重要的。
- 自动管理:栈是由操作系统自动管理的内存区域,它会自动为函数调用分配和释放内存,无需程序员手动管理。这大大简化了编程工作。
- 有限的空间:栈的大小是有限制的,通常由操作系统或编译器设定。如果使用其他数据结构,如链表或数组,可能会导致内存浪费或者溢出的问题。
- 递归调用:栈非常适合处理递归调用的情况。每次函数调用都会在栈上创建一个新的栈帧,这样就可以保证每个函数调用都有自己的局部变量空间,不会互相干扰。
虽然栈有一些限制,比如大小固定、不能动态扩展等,但是对于大多数函数调用场景来说,栈仍然是最优的选择。
JS 中有“堆栈”的概念。跟上面说的“栈”是不是一回事呢?如果不是,那它为什么又叫作“栈”呢?
JS 中:栈内存用来存储变量,堆内存用来存储对象地址。
不是一回事
内存中的“堆栈”是真实存在的物理区,而数据结构“堆栈”只是逻辑上的抽象。
在 JS 中内存可分为两种:代码区、动态数据区
代码区:存储编译后的字节码或可执行的指令
动态数据区:又分为栈、堆。栈存储基本类型的变量以及复杂类型的地址;堆存储复杂类型数据。